In the previous two posts of this series, I shared my experiences with using ChatGPT to create a coding project, which involved some ups and downs. It took 78 prompts and a total of 350 lines of prompts to create a 118-line Typescript project. Moreover, the process took four times longer than coding it by hand. Nevertheless, this was only the beginning of my exploration of the potential of Large Language Models (LLMs) in programming.
Read MoreThe ChatGPT Programming Experience: A Second Attempt
Welcome back to my series on using ChatGPT for programming (written with help of ChatGPT)! In this second installment, I’ll share my experiences using ChatGPT to build a small software project.
Here you can find the chats: https://github.com/juangamnik/chatgpt-schedule/tree/main/chatgpt
I set out with the premise that I would not write more than a few lines of code, leaving most of the work to ChatGPT. Let’s dive into the numbers, the areas where ChatGPT slowed me down, and the moments where it truly shined.
Read MoreLarge Language Models, GPT, and I
This is the first blog post in a row that describes my first experiences with ChatGPT as a pair programmer and assistant for a developer. As you will see, these experiences had some ups and some downs, but all in all – spoiler alert – on the one hand is the advancement in A[G]I (Artificial [General] Intelligence) especially in regard of NLP (Natural Language Processing) using LLM (Large Language Models) and GPT (Generative Pre-trained Transformers) very impressive. On the other hand I had to revise some of the observations (and criticism) I made, just weeks later, since the pace of evolution in the AI scene is so freaking high.
So these are the blog posts of this series:
- This post
- The ChatGPT Programming Experience: A Second Attempt
- The Evolution of Large Language Models in Programming: A Broader Perspective
But let’s start at the beginning (the following text has been created with help of GPT-4)…
Read MoreDiffing and Patching Large Binary Files Part II
After reading my last post a second time I realized that without further explanation the diff-binary.sh and patch-binary.sh scripts look just like a wrapper around a specific rsync call. But there is a little bit more to it. Therefore, this post describes the rationale behind these scripts and enhances them to some extent (with input handling & hashing).
Incremental Backup of Image Files (or: How to Diff and Patch Big Binary Files)
More often than expected, there is a problem for which there should be an easy solution, but a short googling session lets you behind with the hollow feeling that the world let you down… again. But then you put out your unix skills to find a solution for the problem on your own.
Update: There is a Part II to this post, which explains the idea behind the solution shown here
Today is such a day… The problem is as follows: you backup a disk (e.g. the sdcard of a raspberry pi) with dd like this:
$ sudo dd if=/dev/mmcblk0 of=/media/backup/yyyymmdd-raspi-homebridge.img bs=1M
A backup with dd is a bitwise copy, which takes exactly the space of the disk, no matter how empty the block device is. I.e., the dd-image of an sdcard with nominally 16GB takes about 15GB (the usable space of the disk). If the device is more or less empty, the image consists of a lot of zeros and can be compressed with tools like bzip2 very well. In your (i.e., my) case 6 GB are used on the disk. After compressing the image it is less than 2 GB. Sounds great, right? Unfortunately, you are paranoid and want to store the last X backups. Even with a small X, this can get really hungry on your cloud storage. This is the time where your inner voice says: Wouldn’t it be great to store the delta of an old to a new backup, only?
That means, you store the complete (compressed) backup of the most current backup, as it is most likely, that you need it than older ones. The older backups are just deltas to the next-newer backup. Each time a new backup is created, the predecessor image is replaced by a diff/delta between it and the new backup.
There must be a solution for this, right? Meh, at least I couldn’t find that solution. If you found it, please comment below. So, I started some experiments…
Read MoreFind Missing Files in a Backup 2nd Iteration
I already wrote a post about this topic. But as I do at work, I work in an agile manner at home. So here is an update to the post Find Missing Files in a Backup. The script there has been designed to be copied from the clipboard into the terminal. This time, I present you a script, which you may copy to a file, make it executable and reuse it easily. Further on, it fixes some minor issues with the original version (e.g. handling files with spaces and backup folders which are named differently, than the original folder).
For the more general idea of this script, please have a look at the former blog post (see link above). So here it is:
#!/bin/bash
src=$1
tgt=$2
(cd ${src} && ls) | while read file; do
found=$(find $tgt -name "$file" | wc -l)
if [ $found -eq 0 ]; then
echo $file
fi
done
Copy this into a file e.g. named backup-check.sh and give it exec rights:
$ chmod ugo+x backup-check.sh
Afterwards you can use it like this:
$ ./backup-check.sh original/ backup/
Exciting 🤓.
Azure DevOps Wiki Export
Lately I needed to export an Azure DevOps wiki as one PDF. There is a plugin that claims, that it can do this and of course you can export each page in the browser and concat them with tools like pdftk. Unfortunately, the plugin is in a very early stage and I did not have any control over the Azure DevOps instance. The latter felt like loosing…
Hence, I searched for a “computer scientist”-solution. So I downloaded the repo and installed pandoc.
Find Missing Files in a Backup
Long time no write… I had many ideas for blog posts, but no time to write them. Hopefully, this will change soon. Here just a small update… As you know (if you read my blog), I have a “special” way of storing and “backupping” my files. All my documents are stored in a folder named YYYY/ (e.g. 2021) and have the format YYYYMMDD-<some-name>.<some-ending>. I further categorize my files by using macOS tags.
Every year I prepare a folder tax-YYYY/, where I copy all the files with relevance to my tax declaration. But sometimes I am not completely sure whether all the files in there are in my main YYYY/ folders, too. This is, because I copy files from my e-mail (like invoices) and some files, which relate to year YYYY are from YYYY+1, e.g. the proof of social security. So, after finishing the tax declaration I double check, whether every file that belongs to a year made its way into the corresponding folder with a dedicated unix command (here exemplarily for 2019). For sure this can be used to check the completeness of backup folders, too. A recursive variant may even be used to search complete backups for missing duplicates/files. So here is the command.
ls 2019* | while read file; do; \ found=$(find ../2019 -name $file | wc -l); \ if [ $found -eq 0 ]; then; echo $file; fi; \ done
Be aware, that this does only search for a file with the same name. It does not check whether it is not the same file (e.g. due to file changes). This can be done by using a hashing algorithm
Exciting 🤓.
Spring Boot Passthrough JWT with RestTemplate
In a microservice environment it is often the case, that calls from a client to a service result in further calls to other services. One possible scenario is a call to a GraphQL service which gathers information from different backend (REST) services and present it as a cohesive data graph.
In this scenario the user is authenticated to the backend services via OAuth2 (e.g., Keycloak or a Spring Boot OAuth2 server) and the GraphQL service should passthrough the authentication header (a JWT bearer) of incoming requests to the backend services. This way the authentication has to be validated only once in the backend services and as “near” as possible to the (REST) resources.
This is not meant as a replacement for service-to-service authentication, but as an addition if you do not use the full OpenID connect standard with a separate identity token to pass on, but still want to serve verifiable user data to your backend service. In contrast, you may use this to pass through any header (including a identity token). This is just a scenario that I faced.
Read MoreRepair a Damaged Package System after Ubuntu Dist-Upgrade
Happy new year.
My blog runs on a VM at Hetzner with an Ubuntu LTS system. That means 5 years of support… I was running trusty from 2014, so there should be support until 2019. But not every open source software has given you this promise, just the Ubuntanians. So, support for Owncloud run out last year and I thought that the days between years are a good time to switch to a new version.
Hence, I did two dist-upgrades after another from trusty to xenial and from xenial to the current LTS version bionic (every 2 years a new LTS version is coming out). The first upgrade was “successful” with a lot of need for adaption in the configurations afterwards. Then after everything worked again, I did another upgrade, which failed because of this issue.
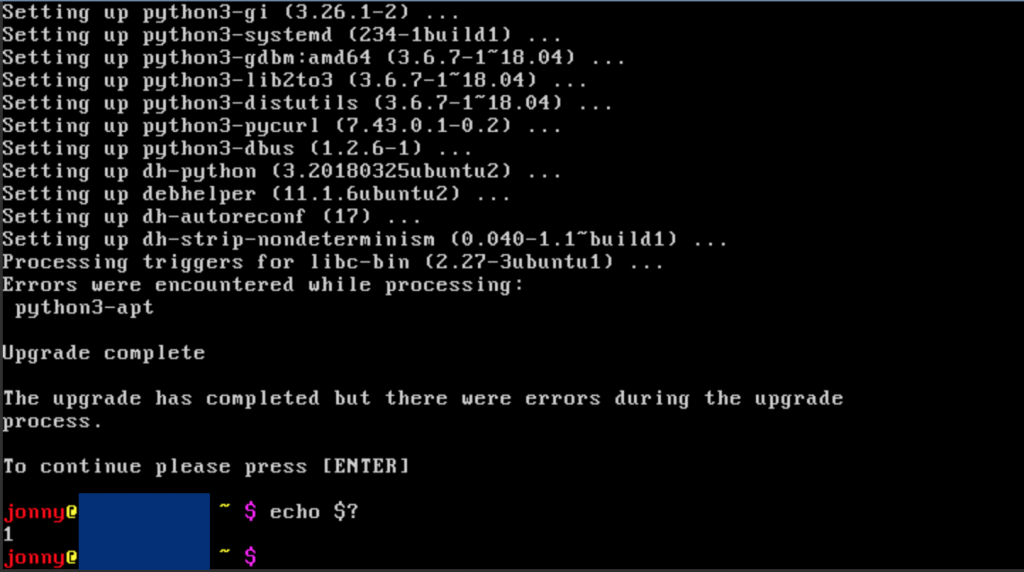
do-release-update.That is, I had to fix a distro upgrade that failed in between… challenge accepted 🤓.
Read More