I bought a new keyboard recently: the Lofree Flow 2 with 84 keys (so a 75% layout) in ISO-DE, with keycaps intended for macOS.
At first glance, that sounds like exactly the right combination for me. Compact, mechanical, pleasant to type on, visually clean, and supposedly Mac-friendly. In practice, however, I ran into a surprisingly annoying problem almost immediately.
On the Q key, the keycap shows the @ symbol. That is already slightly misleading, because on this keyboard, that does not behave the way my muscle memory expects on macOS. Under Windows, this sort of placement often makes sense because Alt+Q can produce @. But on macOS, if your fingers are trained differently, things become awkward fast. Even worse: a wrong combination in that area can easily drift into Cmd+Q, which closes the currently active application. That is irritating, but still survivable.
In my last post I gave an introduction to my overall hardware and software setup for backup. But this was the easy part. Backing up several massive Apple Photos libraries—each overflowing with iPhone snapshots, RAW captures from my system camera, videos, panoramas, and AI-generated art—turns out to be a far more complex endeavor than initially anticipated.
For the impatient… You can find the resulting repository, with one iOS solution (which does not completely satisfy my requirements) as well as a macOS solution (which only runs if my MacBook is “awake”, but besides that is an A+), here: https://github.com/juangamnik/apple_photos_backup/
Still with me? Great, let’s dive into the story… Over months of testing, scripting, and wrestling with encrypted storage quirks, a reliable, fully automated solution has finally taken shape. In this post, I’ll walk you through the entire journey: from the early missteps to the final macOS-based workflow that ensures every original file (complete with sidecar and edit metadata) eventually lands safely in an encrypted, deduplicated long-term archive. Whether you’re juggling multiple family libraries or simply want bulletproof Apple Photos backups, I hope this detailed account of trials and triumphs helps you avoid the pitfalls and understand exactly how the tooling works.
Disclaimer: This issue vanishes, if you have a windows or macOS device running 24/7 with enough disk space to deactivate “optimize space”. If true: don’t read 🤓.
By the way: Apple encourages you to backup your iCloud Photos!
In this post I describe how and why I radically overhauled my backup strategy over the past few years – and which alternatives I consciously ruled out. It is written as a journey (what it was), which hopefully gives you helpful insight, whether my decisions could be yours or not (what is ok for me 🤓). I added takeaway sections, for more general insights.
Over the past two weeks, I’ve been following a number of discussions around recent research by Anthropic — the company behind the Claude language model family. These discussions have played out not only in academic circles, but also across social media platforms and YouTube, with science communicators offering their own takes on what the research means.
I noticed that many of these interpretations diverge significantly, sometimes dramatically, from what the papers actually say (and — by the way — from each other). In particular, some claims struck me as exaggerated or speculative, even though they were presented with great confidence and strong rhetorical framing. Others, while more cautious, also made far-reaching conclusions that aren’t necessarily supported by the evidence.
So I decided to take a closer look at the primary sources—the papers themselves—and compare them to some of the circulating interpretations online. My aim here is to share how I read the papers, highlight where I believe common misunderstandings have occurred, and offer a technically grounded perspective that avoids hype, but also doesn’t dismiss the progress that has clearly been made.
More specifically, this post focuses on the following:
A structured recap of the two Anthropic papers and what they actually demonstrate.
A comparison of two popular YouTube interpretations (by Matthew Berman and Sabine Hossenfelder), which offer almost opposing takes.
A short excursion on LLMs and how they work (and why)
My own analysis of why certain assumptions — about self-awareness, internal reasoning, and “honesty” in LLMs — may not be warranted based on the research.
In writing this, I’m not claiming to offer the final word. But I do think it’s important to take a step back from the soundbites and really ask: What do these findings actually show? And what might they not show?
If you’ve found yourself wondering whether LLMs are secretly reasoning behind our backs, or whether it’s just a glorified autocomplete—this post might help you sort signal from noise.
Do you know the feeling of standing helplessly in front of a technical problem, with modern devices leaving you no room to intervene in the solution because they are closed systems? It feels like you have no control and are at the mercy of the manufacturer. I work in IT myself and have carried out many software projects in various roles throughout my life. Actually, I am not willing— and I also tell all my friends and acquaintances— to help with technical issues on home devices like smartphones, computers, or laptops. My usual saying is: “I’d rather help you move than fix a computer problem.”
But what if it’s your own device to deal with? Then you have to take care of it. Many problems can be solved with extensive Googling or by asking an AI of your choice. I recently encountered an issue with my iPad that turned out to be tricky to fix.
Let me briefly explain the problem: Despite having automatic updates enabled, I hadn’t updated my iPad for a long time. The latest iPadOS version was 18.3.2, but I was still running 16.6.1 without realizing it. That really surprised me. When I tried to manually trigger the update, the iPad downloaded it for a long time, prepared the update even longer, restarted, but remained on the old operating system.
TL;DR: The final solution was to reset the iPad, set it up as a new device, immediately install the update, and then restore it from the last backup. Often, an update fails to complete correctly in a specific system state. By resetting the device, updating to the latest iPadOS version, and then restoring the backup, I was able to resolve the issue.
Welcome back to my series on using ChatGPT for programming (written with help of ChatGPT)! In this second installment, I’ll share my experiences using ChatGPT to build a small software project.
I set out with the premise that I would not write more than a few lines of code, leaving most of the work to ChatGPT. Let’s dive into the numbers, the areas where ChatGPT slowed me down, and the moments where it truly shined.
This is the first blog post in a row that describes my first experiences with ChatGPT as a pair programmer and assistant for a developer. As you will see, these experiences had some ups and some downs, but all in all – spoiler alert – on the one hand is the advancement in A[G]I (Artificial [General] Intelligence) especially in regard of NLP (Natural Language Processing) using LLM (Large Language Models) and GPT (Generative Pre-trained Transformers) very impressive. On the other hand I had to revise some of the observations (and criticism) I made, just weeks later, since the pace of evolution in the AI scene is so freaking high.
In a microservice environment it is often the case, that calls from a client to a service result in further calls to other services. One possible scenario is a call to a GraphQL service which gathers information from different backend (REST) services and present it as a cohesive data graph.
In this scenario the user is authenticated to the backend services via OAuth2 (e.g., Keycloak or a Spring Boot OAuth2 server) and the GraphQL service should passthrough the authentication header (a JWT bearer) of incoming requests to the backend services. This way the authentication has to be validated only once in the backend services and as “near” as possible to the (REST) resources.
This is not meant as a replacement for service-to-service authentication, but as an addition if you do not use the full OpenID connect standard with a separate identity token to pass on, but still want to serve verifiable user data to your backend service. In contrast, you may use this to pass through any header (including a identity token). This is just a scenario that I faced.
My blog runs on a VM at Hetzner with an Ubuntu LTS system. That means 5 years of support… I was running trusty from 2014, so there should be support until 2019. But not every open source software has given you this promise, just the Ubuntanians. So, support for Owncloud run out last year and I thought that the days between years are a good time to switch to a new version.
Hence, I did two dist-upgrades after another from trusty to xenial and from xenial to the current LTS version bionic (every 2 years a new LTS version is coming out). The first upgrade was “successful” with a lot of need for adaption in the configurations afterwards. Then after everything worked again, I did another upgrade, which failed because of this issue.
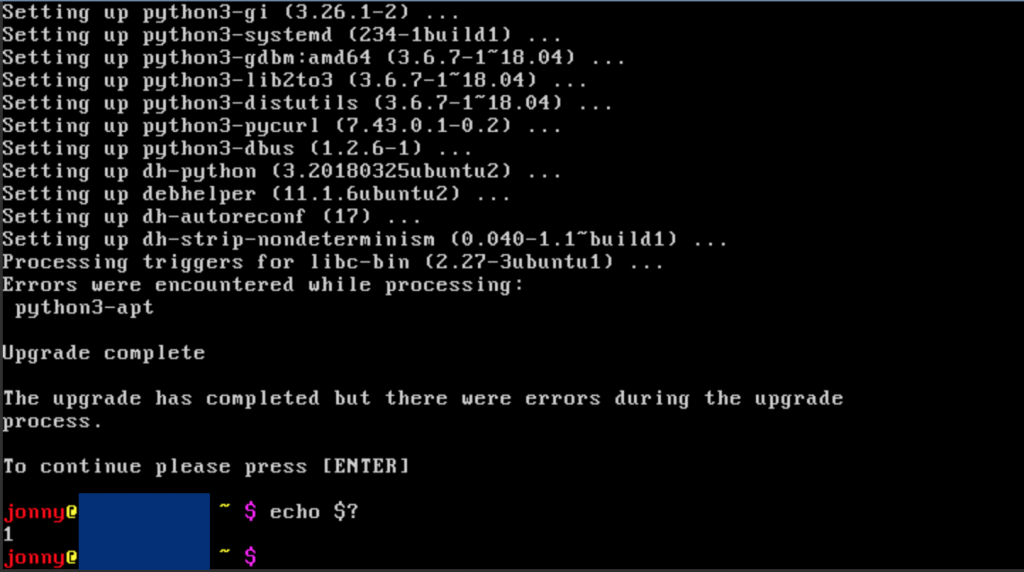
You do not want your system showing you such a message during do-release-update.
That is, I had to fix a distro upgrade that failed in between… challenge accepted 🤓.
For quite some time I have a paper-free office (at home). I still physically file the papers I get, but in addition I scan all the paper documents, tag them and put them in a folder. I use a very easy system. For the very recent documents (and the ones work in progress) I have a draft folder. Furthermore, there is exactly one document folder per year and I store everything in there (incoming and outgoing documents, scanned ones and ones that I get mailed, even some printed to PDF emails for document-like emails). Each file has a common naming scheme. There is one part that is relevant for this post: at the beginning of each file I put the date of the document in the format YYYYMMDD. This way, the documents are ordered chronologically in a year, if I sort them by name. There is a lot more to my filing system and if someone is interested, please leave a comment, but for this post, this should be enough about my way of filing documents (digitally).
The issue I would like to address here is, that the date when I scanned a file and the “real” date of the document diverges. Sometimes it even happens, that the creation time of two scanned files are in “the real world” in one order, but the scan-/creation time is the other way around. I do not like this situation. Therefore, each year when I “finish the year”, I run a script (on macOS), which adapts the ctimeto the date-part in the name of the file (a one-liner, which I put on 5 lines, for better readability):
find . -name "2017*" | while read file; \
do thedate=$(echo "$file" | \
sed -E 's/^[^0-9]*([0-9]+).*$/\1/'); \
touch -t ${thedate}0000 $file; \
done
If you have another unix-based System with sed you can use -r instead of -E. I am unsure why this option behaves differently on macOS although I installed (and use) GNU sed installed via home brew.